1. 概要
与大部分设备厂商一样,Google也面临着AOSP(Android Open Source Project)多分支的管理问题, AOSP需要使用多个分支来维护不同的Android版本,设备厂商除了要接受Android版本的不同分支,还要使用更多的分支来处理不同设备之间的差异。 维护多个分支始终是一项繁重的任务,当设备厂商的产品越来越多,而且还存在跨多个Android版本开发的时候(既有基于Android 4.4的设备,也有基于Android 5.0的设备),多分支管理简直就是噩梦。
一般而言,设备厂商都是尽可能地减少分支,所以,在设备厂商的代码中,会有很多手段来避免新增分支:
-
编译时过滤。通过编译开关来兼容代码差异,以便于一个分支下,通过不同的开关配置,编译出不同的版本。静态编译开关以MTK的方案为代表,HTC、SONY等大厂商都有采用这种方式。
-
运行时反射。多份功能类似的代码都经过编译,但运行时,根据配置信息,选择加载的类。运行时反射以CM的方案为代表,尤其是RIL层的反射框架极为精彩。
-
基于SDK开发。很多应用层的开发都转向了基于SDK或基于厂商自己的中间件。即便框架层有差异,需要新增分支,但应用层仍然是共分支的,不需要额外增加。
以上手段能够减少分支的膨胀,但并不能完全避免新增分支。不同的芯片厂商都会提供自己的平台方案,譬如MTK, QCOM, SAMSUNG等,设备厂商通常都不是完全基于AOSP进行开发,而是基于不同芯片的平台方案。 不同的芯片平台方案的差异,导致设备厂商不得不额外新增分支,如此一来,多分支管理的噩梦依旧挥之不去。
本文分析了AOSP代码的管理方式,包括AOSP的分支结构和发布策略。面对多分支,AOSP采用了代码自动合并的技术来降低维护成本,其背后的技术原理或许能够舒缓一下设备厂商面对多分支的烦恼。
2. AOSP的代码线、分支和发布
在每一次Android发布新版本的时间段内,AOSP会存在多条代码线(codelines)和一个最新的发布分支(release)。 代码线可以理解为AOSP维护代码的一个维度,它可能包含多个分支(branches)。 譬如Android先发布了4.4版本(对应kitkat-release分支),随后又发布了4.4.1版本(对应kitkat-mr1-release分支), 那么这两个版本,就可以理解为同一条代码线下的不同分支。
当最新的Android版本N发布时,厂商和开发者就可以基于最新的发布分支(N release)来解决Bug,适配机型。与此同时,AOSP内部仍然在演进Android版本N+1。
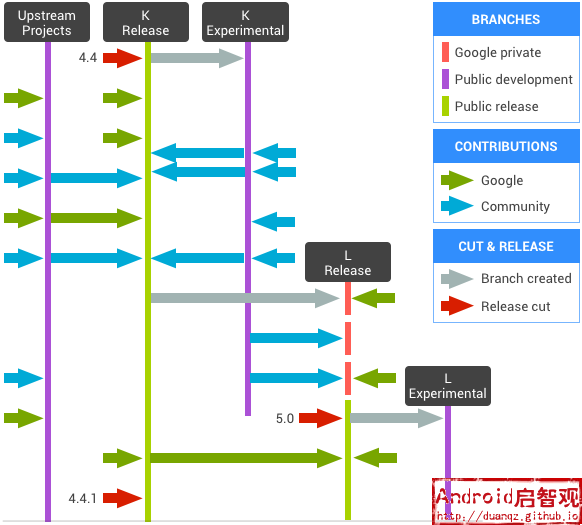
-
Upstream Projects这条代码线表示Android的上游项目,因为Android本身也利用的很多开源项目(譬如Linux Kernel、Webkit、external目录下的项目)会有代码更新,所以,Android会定期从这些开源项目中移植最新的代码。
-
K Release这条代码线用于Kitkat的版本发布。每一个Kitkat小版本的发布,都是基于K Release这条代码线。譬如,4.4发布后(对应kitkcat-release分支),OEM厂商基于kitkat-release分支来适配机型。 4.4发布后,K Release代码线并没有停止向前,Google官方会持续做一些Bug修复,会从Upstream Projects选择代码更新,也会从K Experimental代码线选择代码,直到可以发布下一个新版本4.4.1。 每一次新版本发布,就意味着Android的一个正式版,伴随而来的是SDK版本和Android API版本的升级。
-
K Experimental这条代码线用于实验最新的特性。AOSP会从Android社区选择一些新功能或是Bug修复放到该代码线上。 Android社区一般是由第三方合作厂商来贡献代码,譬如HTC、Moto、SAMSUNG等一些大厂;还有一些活跃的基于AOSP的第三方项目,譬如CyanogenMod。 当一个Android版本发布后,就会创建新的Experimental分支,譬如4.4发布,就会基于4.4的发布分支新建一个K Experimental分支。 当第三方合入K Experimental分支的代码经过一段时间达到稳定状态,被验证通过后,就会合入K Release中的分支,作为下一个发布版本4.4.1的新入代码。
-
L Release这条代码线用于Lollipop的版本发布。在K Release代码线发布了4.4后,Google内部已经在运作Lollipop的5.0版本了(对应分支lollipop-release), 在5.0正式发布之前,L Release代码线都是非公开的,Google也会从K Experimental代码线选择性的合并代码。 直到5.0正式发布,L Experimental代码线构建,又重新进入了同样的开发流程。
总体而言,AOSP的代码管理涉及到以下几个方面:
-
多代码线并存:版本
N的发布代码线和实验代码线,版本N+1的发布代码线,第三方开源代码线。同一条代码线可能存在多个多支,在一个多分支的环境下,就会存在”一个改动适应于哪些分支”的问题。 -
两方代码合入:Google官方和第三方社区Community,第三方社区的构成元素很多,这也体现了Android的开源特性:“众人拾柴火焰高”
-
控制版本发布:任何时候,都只有一个最新的发布版本,但内部会有多个版本齐头并进。
N+1版本在发布以前,并非开源的,完全由Google内部主导,虽然包含很多取自于开源社区的代码,但Google的态度是“取之有道,用之有度”。
3. AOSP的代码自动流
同时维护多个分支,意味着在一个分支上的变更,也可能适应于其他分支,这种情况下,开发人员可以在其他分支上提交相同的内容。 然而,随着分支数量的膨胀,重复提交不仅繁琐而且容易遗漏。因此,有必要引入自动提交的机制:当一个分支上有变更发生时,自动将这个变更记录提交到到其他分支。
Android采用git merge的方式,自动将一个分支的改动合并到其他分支。从整个分支来看,就是代码从一个分支上流向了其他分支,流的起点称为上游分支(upstream),流的终点称为下游分支(downstream)。
然而,自动代码流虽然了避免了人工重复地提交,但也引入了新的问题:有一些改动仅适应于上游分支,自动流向下游分支会导致出错。因此,还需要对自动流进行控制。
在AOSP的提交记录中(譬如:lollipop-release分支),
经常可以看到DO NOT MERGE关键字,为什么提交记录中会出现这种关键字?有什么用途呢?
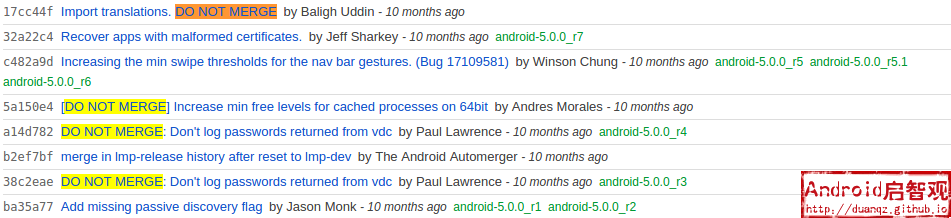
来看一下AOSP的官方负责人Jean-Baptiste Queru的解释:
We (Google) routinely develop on multiple branches at the same time. In order to make sure that the later branch (e.g. ics-mr1) contains all the new features and bugfixes developed in an older branch (e.g.ics-mr0), we have a server that automatically takes every commit made in ics-mr0 and merges it into ics-mr1. However, sometimes the engineer making a change in ics-mr0 knows that this change doesn’t apply to ics-mr1, e.g. because a similar issue was fixed differently in ics-mr1 and the fix from ics-mr0 wasn’t necessary. In that case, the engineer includes the words “do not merge” in their change description, and the auto-merger performs a “git merge -s ours” instead of “git merge” when handling that change. There’s a bit more complexity involved, but that’s the high-level view.
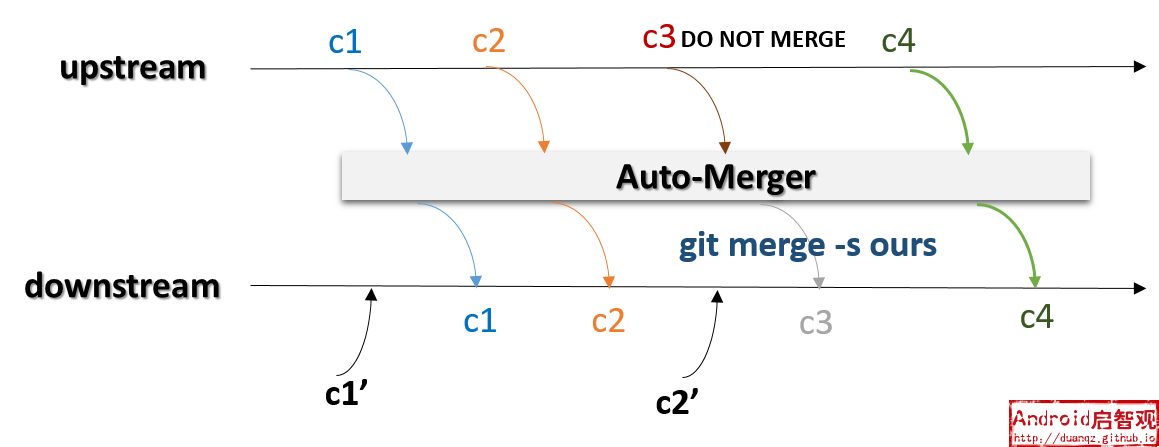
在上下游分支之间,有一个自动合并代码的工具auto-merger,对于上游分支的每一个提交而言,都会通过git merge命令将提交内容自动合并到下游分支。
不需要合并到下游分支的提交,可以通过在提交注解(Comments)中加入DO NOT MERGE关键字,auto-merger如果遇到此关键字,则使用git merge -s ours来合并这个提交。
达到的效果是:提交记录合并到下游分支了,但提交所涉及到的代码改动没有合并。
那么问题来了,将一个分支的提交合并到另一个分支的方法有很多,诸如cherry-pick, rebase, format-patch和am等git命令都能够实现,但为什么AOSP采用的是git merge的方式? 而且,如果遇到DO NOT MERGE关键字,不往下游分支合并就可以了,为什么还要采用git merge -s ours这种方式?
我们的场景是将上游分支(upstream)的代码合并到下游分支(downstream),下面我们来分析一下几种代码合并方式在同一个场景下的异同。
3.1 cherry-pick
在downstream上,使用cherry-pick从upstream选择所需要的提交
$ git cherry-pick E
$ git cherry-pick F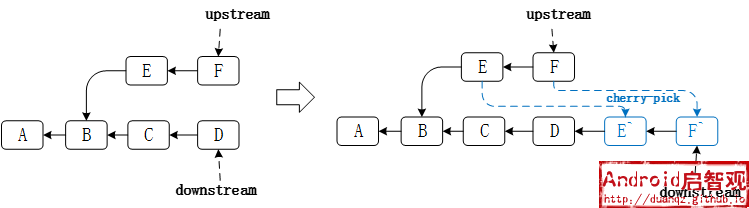
上游分支的提交 E 和 F ,会依次重新提交到下游分支,如果产生冲突,则cherry-pick失败,需要解决冲突后重新提交,直到产生新的提交记录 E’ 和 F’ 。 新提交的Commit ID(提交记录的SHA1)已经发生了变化,即便改动内容完全一样,Commit ID与原来upstream上的不一样。
这种方式实际上也可以通过format-patch和am和来实现,同样做到了从上游分支选择所需要的提交记录,合并到下游分支,Commit ID也会发生变化。
$ git checkout upstream
$ git format-patch E,F # 在上游分支,生成E,F两个改动的patch
$ git checkout downstream
$ git am # 在下游分支,应用已有的patch我们再进一步考虑,基于提交 D 又拉出了下游分支downstream2,并且有一个新增的提交 H, 仍然需要将upstream的改动合并到downstream2上。

这时,仍然可以使用cherry-pick的方式,downstream2分支将会出现新的提交 E’’ 和 F’’ , 与之前的Commit ID都不同。
每一次当上游分支有新的提交时,都需要将其cherry-pick到所有的下游分支。虽然,这种方式能够实现自动提交,让提交记录流起来, 但随着上游分支提交的不断增多,它与下游分支渐行渐远,要向前追溯很远才能找到公共的父提交 B 。此时,噩梦就来了:
-
如果使用merge将upstream合并到downstream,则会产生非常多的冲突。因为merge会找到两个分支的公共父提交,然后做一个三路合并,upstream和downstream的公共父提交早已远在 B 。
-
如果在downstream演进一段时间后,基于某个提交又拉出了新的下游分支downstream3,那很难精确的找到应该从upstream的哪个提交开始cherry-pick,因为downstream上已经包含了若干upstream的提交内容; 如果又重新开始从公共父提交 B 开始 cherry-pick, 那同样可能产生很多冲突,因为经过一段时间的开发,提交内容的变化已经很大。
-
如果发现downstream更加适合做downstream2的上游分支(很多提交只适应于downstream和downstream2,不适合于upstream),那么需要重新建立上、下游分支的关系。 downstream的改动很难精确的cherry-pick到downstream2,因为downstream和downstream2相当于两个独立演进的分支,即便它们的代码改动都差不多(都是从upstream上cherry-pick而来,但两条分支线并没有交合)。 同样,也无法将downstream merge到downstream2,因为它们的公共父提交早已远在 D 。
3.2 rebase
在downstream上,使用rebase,将downstream变基到upstream
$ git rebase upstream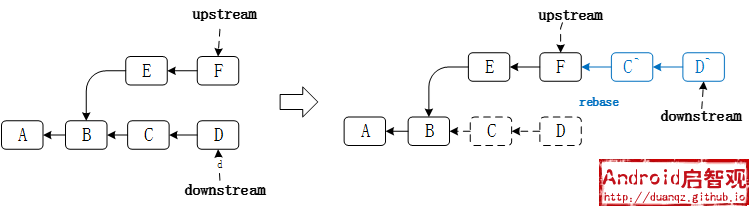
在downstream上使用rebase,表示要改变当前的基节点的位置,通过rebase到upstream,就意味着将基节点切换到upstream的最新提交 F。 本来downstream和upstream公共的父节点是 B , 使用完rebase后,则会将 C 和 D 两个提交记录挑出来,重新提交到 F 之后, 这同样会生成两个新的提交记录 C’ 和 C’ , Commit ID 与之前 C 和 D 的是不同的。
再进一步考虑,基于提交 D 拉出下游分支downstream2,新增提交 H :

这时,继续使用rebase,将upstream合并到downstream2,会出现新的提交 C’’ , D’’ , H’‘, 与之前的Commit ID都不同。
每次当上游分支有新的提交时,都需要重新rebase到上游分支最新的提交,所有下游分支公共父亲节点之后都需要被重新提交一次。 一旦中间某一次提交产生冲突,就会停下来,直到冲突解决完毕,才能继续rebase。
这种方式不适合代码自动流:
-
rebase中断,需要人工参与解决冲突。当分支演进到一定程度时,中断的概率非常高,需要大量的人工参与,也就丧失了代码自动提交的意义。
-
downstream和downstream2两条分支虽然代码改动差不多,但实际上是两条差异很大的分支,因为它们的Commit ID不同。 如果要将这两条分支作为上、下游关系,面临着与cherry-pick同样窘境。
3.3 merge
在downstream上,使用merge,将upstream和提交合并到downstream
$ git merge upstream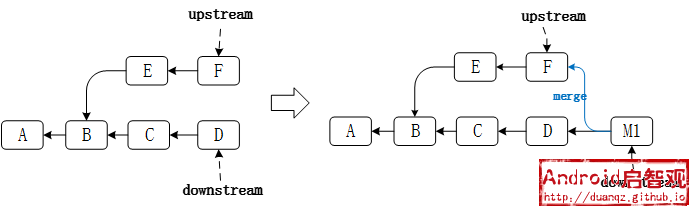
upstream和downstream两个分支merge,会出现一个新的提交 M1 , 它的父提交有两个,分别是 D 和 F。 如果产生冲突,则会一次性提示所有代码改动产生的冲突,这与rebase不一样,有一个很形象的比喻来形容merge和rebase进行代码合并的区别:
注意:将一堆玩具整理到一个箱子中,rebase是一件一件挪,如果箱子满了(产生冲突),则需要整理一下箱子,腾出空间,再接着挪; 而merge是一股脑将玩具扔到箱子中,箱子满了,再一起整理。
一次merge操作不一定会生成新的合并提交 M1, 默认情况下,git merge是采用fast-forward模式的,只是改变指针位置。
如果不出现冲突,则分支图中不会出现分叉的情况,还是保持所有的提交一条直线。这种情况下并不会产生新的提交记录, E 和 F 还是保留了原来的Commit ID。
再进一步考虑,基于downstream的提交记录 D 又拉了新的分支downstream2 ,并增加了新的提交 H , 仍然采用merge将upstream合并到downstream2:
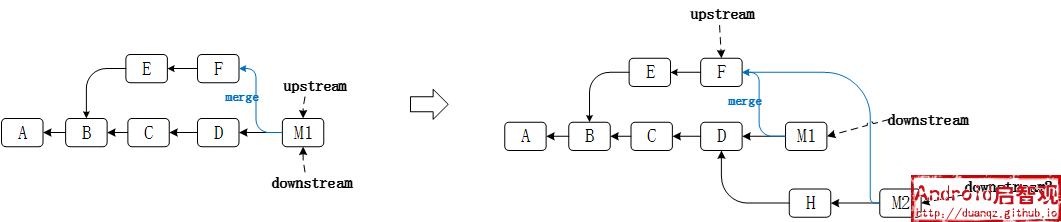
这时产生了一个新的合并提交 M2 , 它的父提交是 F 和 H 。downstream和downstreanm2的公共父提交 F。
这里有一个细节,upstream合并到downstream2,相当于(B, F, H)的三路合并,在此之前,将upstream合并到downstream,相当于(B, F, D)的三路合并。
E, F与C, D合并可能会产生冲突,一旦冲突解决,则冲突解决的方法就被git记录下来了,再将E, F与C, D, H合并时,会利用之前解决的冲突,这样冲突数量会减少很多。
具体可以参见git-rerere - Reuse recorded resolution of conflicted merges机制。
随着upstream的不断演进,会不断地merge到downstream和downstream2, 所有的下游分支的公共父提交始终都跟踪到upstream的最新提交记录。
相比采用cherry-pick和rebase实现代码自动流,merge的方式更适应多分支的场景:
-
上游分支的Commit ID得以保留,在使用Gerrit进行代码Review的时候,旧的Commit ID并不会产生新的Review任务。所以在使用Gerrit进行代码审查的场景下,并不会增加无效的Review任务。
-
Change-ID:Gerrit针对每一个Review任务,引入了一个Change-ID,每一个提交上传到Gerrit,都会对应到一个Change-ID, 为了区分于Commit-ID,Gerrit设定Change-ID都是以大写字母 “I” 打头的。 Change-ID与Commit-ID并非一一对应的,每一个Commit-ID都会关联到一个Change-ID,但Change-ID可以关联到多个Commit-ID
-
Patch-Set:当前需要Review的改动内容。一个Change-ID关联多个Commit-ID,就是通过Patch-Set来表现的,当通过git commit –amend命令修正上一次的提交并上传时, Commit-ID已经发生了变化,但仍可以保持Change-ID不变,这样,在Gerrit原来的Review任务下,就会出现新的Patch-Set。修正多少次,就会出现多少个Patch-Set, 可以理解,只有最后一次修正才是我们想要的结果,所以,在所有的Patch-Set中,只有最新的一个是真正有用的,能够合并的。
-
-
增加一个下游分支的维护成本并不高,利用
git-rerere机制,只需要解决少量冲突,就能从上游分支合并最新的代码。后续演进,再使用merge自动从上游分支合并代码即可。 -
多个下游分支之间可以灵活进行合并,譬如,需要将downstream作为downstream2的上游分支,只需要在downstream2分支上merge一下downstream即可, 因为多个下游分支的最近公共父提交就是上游分支的最新提交(上图中的 F ),并不需要向前追溯很远。
3.4 merge strategy
我们分析了采用merge方式实现代码自动流的原因。当然,cherry-pick和rebase也有自己的用武之地,它们能够做到对每个提交进行精确控制,但merge做不到, 面对有提交不需要自动合并到下游分支的情况,merge需要提供一种策略。
AOSP就是通过提交描述中的DO NOT MERGE关键字,来判断当前提交是否需要往下游分支合并。前文中我们提到了git merge -s ours的命令,实际上就是merge的一种分支合并策略。
如果某个提交不需要合并到下游分支,那这个提交还必须得告诉git,否则,下一次再使用merge时,还是会找到上、下游分支的上一次的公共父提交,将这个提交的代码改动合并到下游。
-s ours就表示合并这个提交记录,但忽略这个提交的代码修改。从整个提交记录上看,分支图中还是进行的一次merge操作。
这样一来,上、下游分支的公共父提交的位置发生了变化,下一次使用merge时,就会从这个公共父提交开始进行三路合并,不会引入-s ours这个提交的代码改动。
4. 总结
本文介绍了AOSP的代码管理方式,深入分析了代码自动流的技术方案,通过merge实现代码自动流,能够降低多分支的维护成本。 诚然,要真正做到有效的代码自动流,仅merge操作是不够的,需要在多分支之间搭建一套代码自动合并的方案,譬如:代码自动提交的触发时机、冲突的处理办法都是需要考虑的问题, 另外,丰富一下merge操作提交时的注释内容,也能够帮助我们更好的回溯问题。
本文对merge, cherry-pick和rebase操作进行了对比,但这只是在分支合并的场景下,并不是为了说明merge就是万能的。cherry-pick和rebase操作都是很有用的命令, 譬如在topic分支上进行开发,可以使用rebase命令与master分支保持同步,而且所有的提交记录都是线性的,不像merge操作一样,形成复杂的网状,网状的分支图会使得历史提交记录很难被追溯。
AOSP的代码自动流策略,还比较自然,不同Android版本之间的代码流起来,冲突也不会特别多,如果冲突很多,肯定也就说明问题来了,代码差异越大只会导致越来越难维护,这自然不是AOSP期望看到的。 对于设备厂商而言,面对的情况比AOSP要复杂,在跨Android版本、跨芯片平台的场景下,分支只会更多,差异也只会更大。